Optimal Control (OC) problems seek a dynamically feasible trajectory that minimizes a cost functional defined along the trajectory, which is of fundamental importance in robotics, and is the basis for numerous research topics such as agile flight of drones, dynamic balancing of legged robots, trajectory planning for multiple robots or information search. Many famous OC approaches, such as Linear Quadratic Regulator (LQR), iterative LQR (iLQR), and differential dynamic programming (DDP), often assume a fixed planning horizon, which means that the amount of time for the trajectory is fixed as an input parameter. This limits their usage especially in applications such as drone racing, where the horizon itself is part of the objective to be minimized, and users would have to tune this horizon parameters via trail-and-error. While these famous OC methods (e.g. LQR, DDP) are well studied, enjoying beautiful theoretic properties and are deployed on various robots, their horizon-optimal counterparts are still undiscovered, which motivates this project.
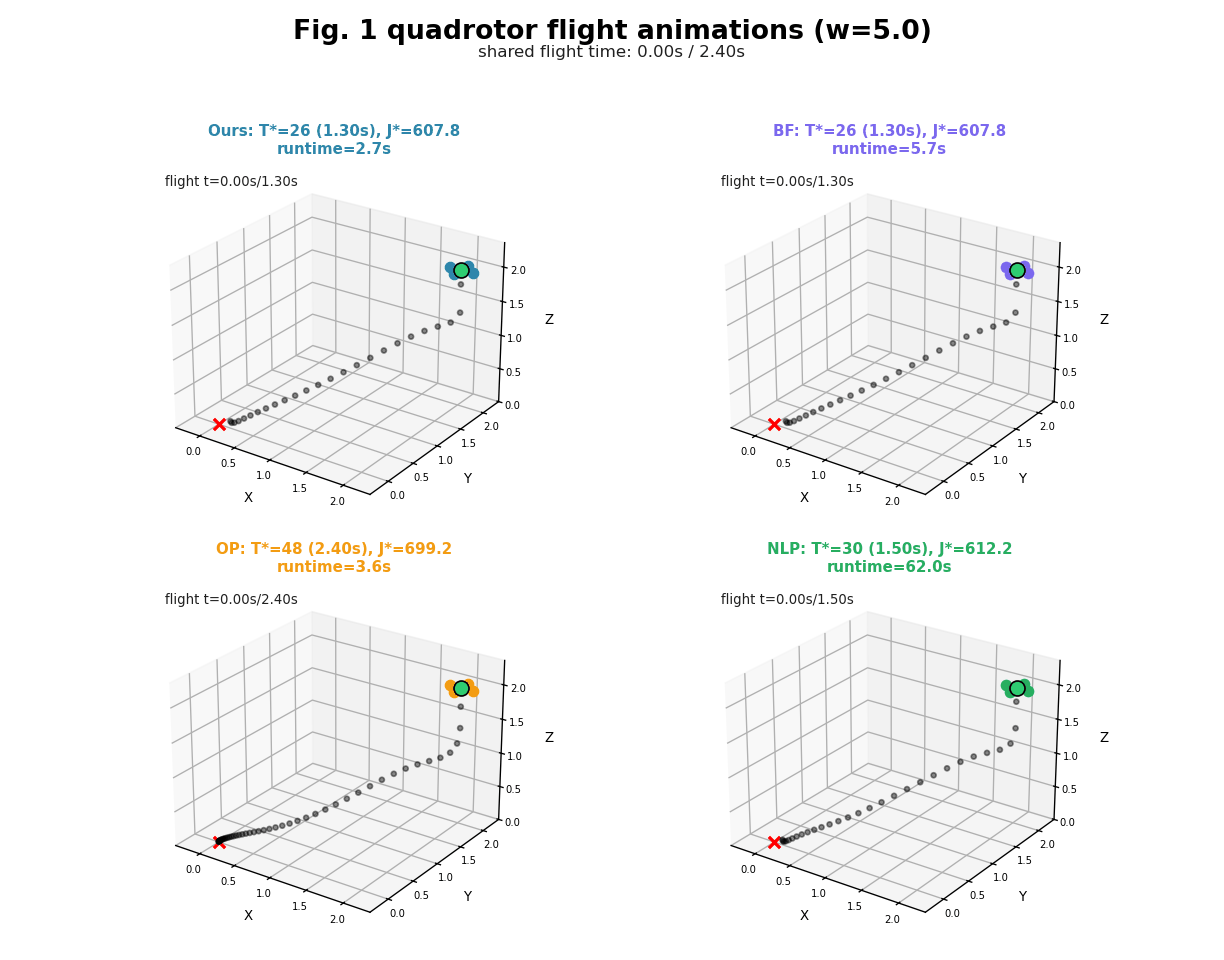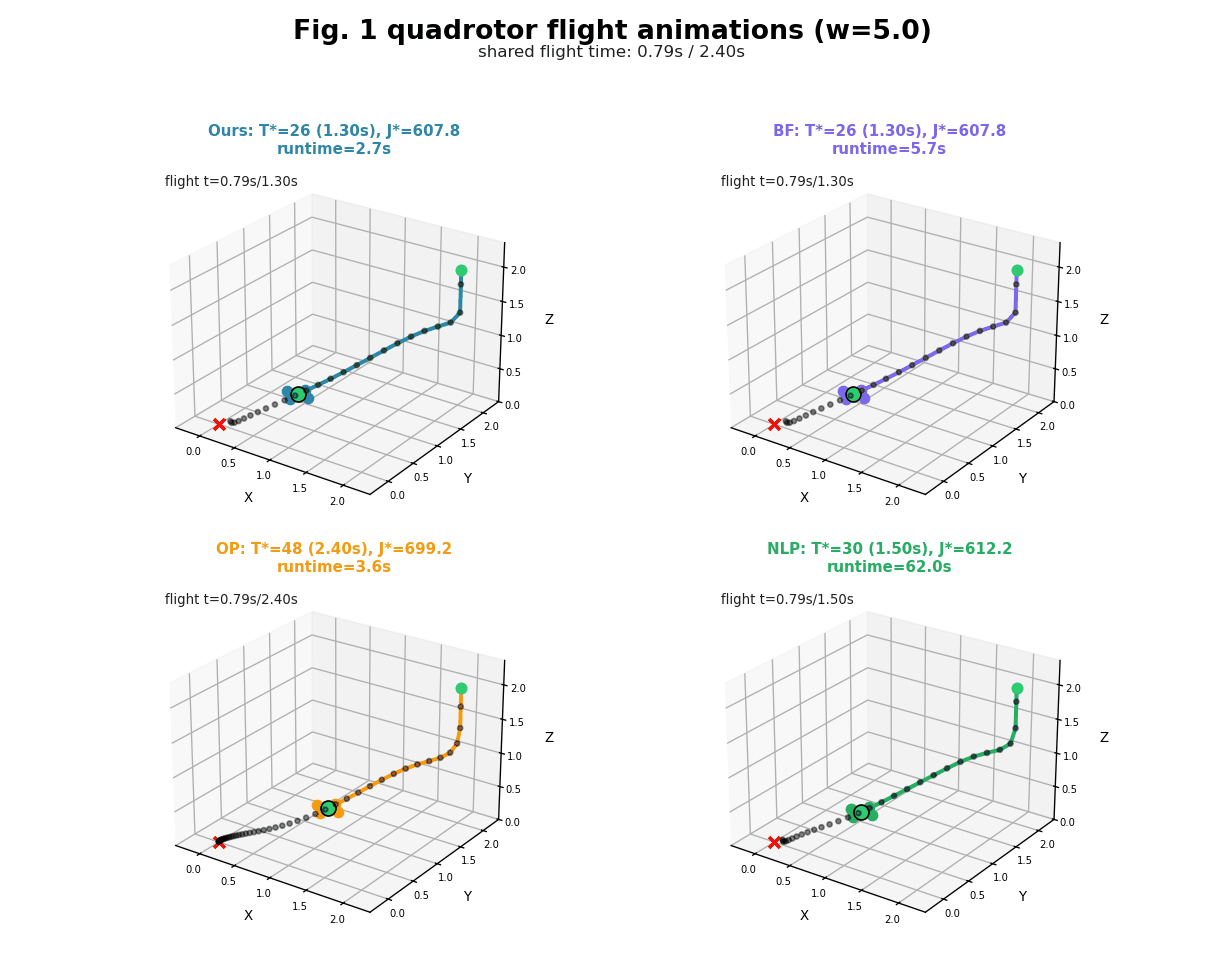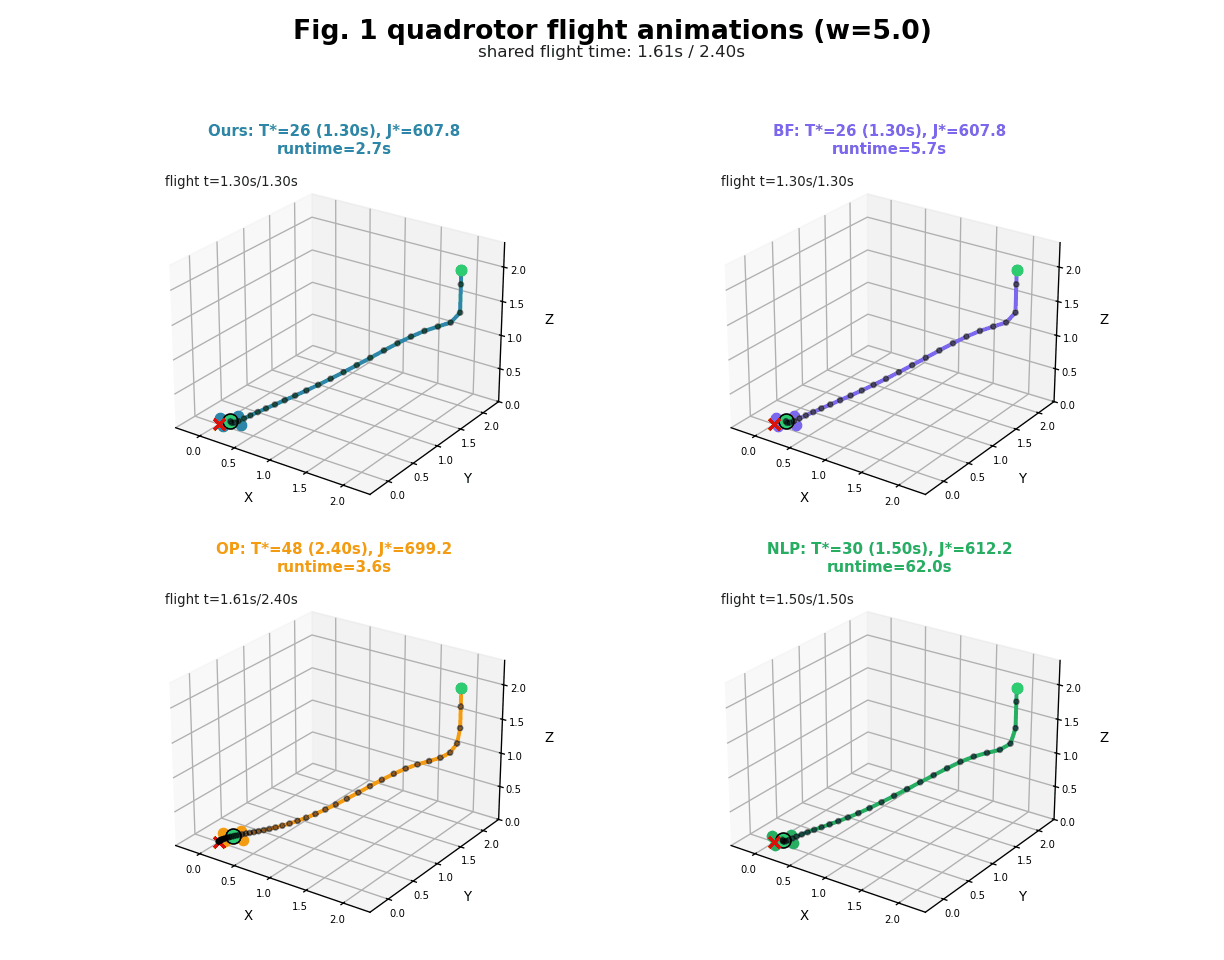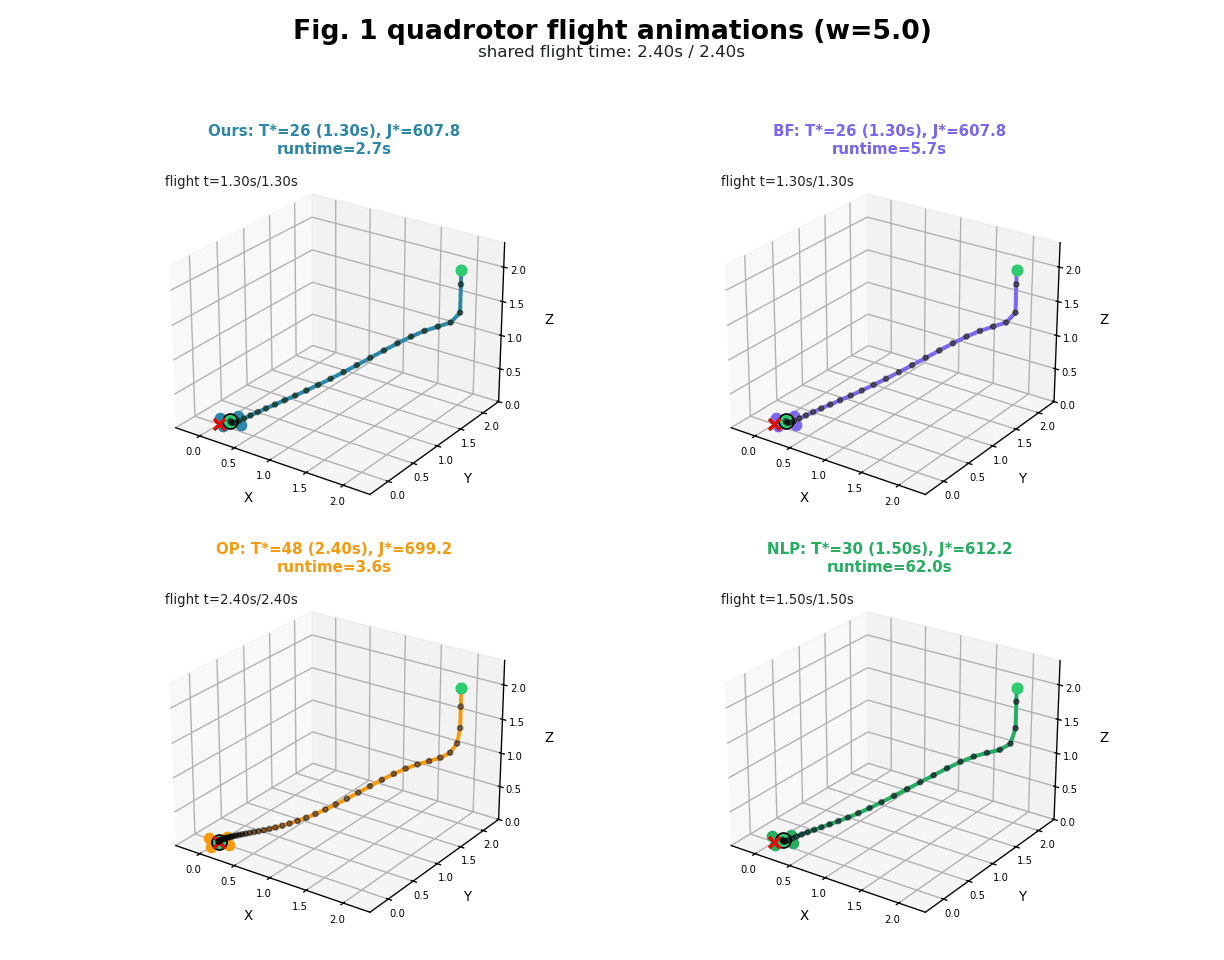
In this project, we develop a new approach which we call it HOP (Horizon-Optimal Planning/Programming). The key idea in HOP is based on our observation that, the well-known Riccati recursion for LQR can be reformulated into a form of Linear Fractional Transformation (LFT), which enjoys the structure that enables efficient computation by reusing a new form of value functions during the backwards pass, even for non-stationary dynamics and costs. Based on this idea, we develop HOP-LQR that can solve Horizon-Optimal Time-Varying LQR problem to optimality by selecting a best horizon from a pre-specified maximum integer horizon N. While naively solving the problem requires quadratic worst-case runtime complexity $O(N^2)$, we show that our HOP-LQR reduces the runtime complexity to linear $O(N)$, which is same as a regular Riccati recursion for the basic LQR problem.
The ability to handle time-varying LQR naturally leads to extensions to nonlinear systems by linearization, since linearizing the nonlinear dynamics along a trajectory at different times or positions can naturally lead to time-varying dynamics. With that in mind, we further develop HOP-DDP by introducing an augmented state space formulation, which allows solving horizon-optimal OC problems with general nonlinear dynamics and non-quadratic costs efficiently.
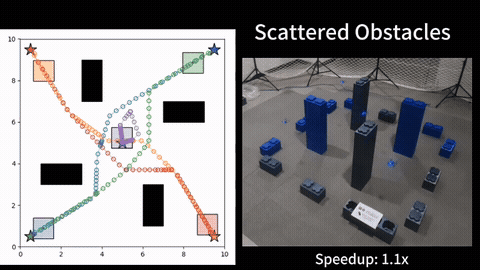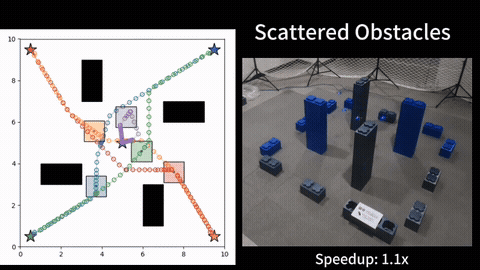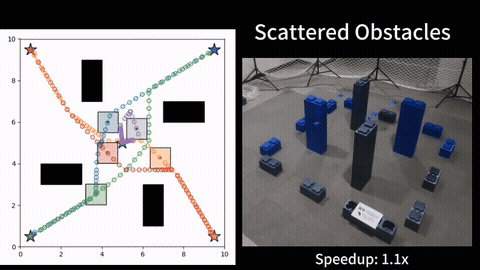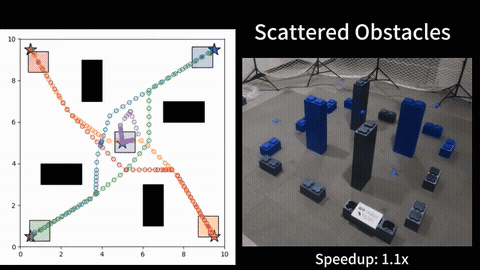
We compare our HOP against several baselines on different dynamic systems. Experimental results show that, our HOP always finds the same optimal solution as a naive brute force baseline method, while running up to 40 times faster, for both linear and nonlinear systems. In comparison to the shift horizon baseline method, while this baseline has similar runtime as ours, this baseline gets stuck in worse local minima for almost all instances when the dynamics is nonlinear, while our HOP and the brute force baseline always find a better local minima with up to 7\% cheaper costs. More detail can be found in our paper [1].